NoSQL databases and Hackathons
Today I will talk about the conceptual differences in the ways data is usually stored and my stint learning one of the more novel ways that are currently taking the world by storm. I do not pretend to be an expert in either of the model’s that I will describe, but if this clarifies anyone’s confusion then it is worth writing.
The Relational Model
The most common way to store data in a computer today is in a relational database. This means that data is stored using the relational model. Very basically the relational model relies on storing the information in a series of tuples, which are grouped into relations. The values of each tuple are attributes of it. This means that the model in theory consists of only tuples of information that are linked. Based on this model it is possible to perform calculations on the tuples which will yield more tuples, which hopefully tell you something.
In practice the relational model is implemented in a Relational Database Management System (RDMS) The tuples are called rows and a group of tuples is called a table. Every column of the table is and attribute, and describes a particular set of values that tuples in that table have. This system uses a language to declare data and specify a query about said data. This is the plain old SQL everyone learns in college. So for example, if we were looking at a data set that described the characteristics of soccer players, the tuples would be an entire row of the table (so all of the information of the soccer player), each relation would be a table itself, and the values of each attribute form a column
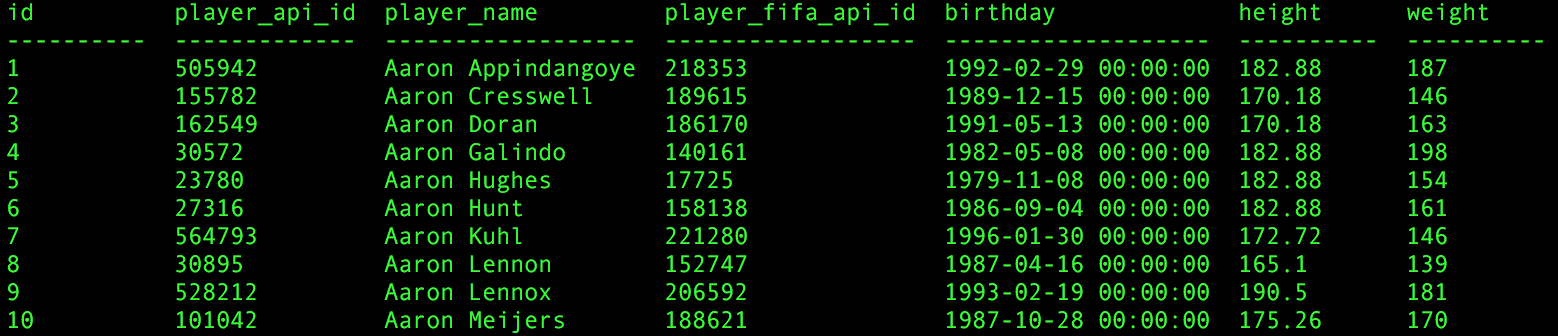
Credit: kaggle.com european soccer dataset.
A query in a relational database performs operations between tables or between rows (or both).
NoSQL databases
Now, a NoSQL database is one that is not theoretically based on the relational model. This means that it chooses to store data in a different manner, typically without rows and tables, or at least without a strict ordering of them. There are many types of these; some examples are document and key-value databases.
Another example is that of a graph database. In a graph database, each node of the graph has a set of attributes, and each edge from one node to another is a relation (not to be confused with the above definition of a relation in a relational model database), which means that any sort of query on the graph will be a traversal of the graph. If we are looking at a dataset of the film industry, an edge might describe the relation that a person (node) has had in a production (also a node).
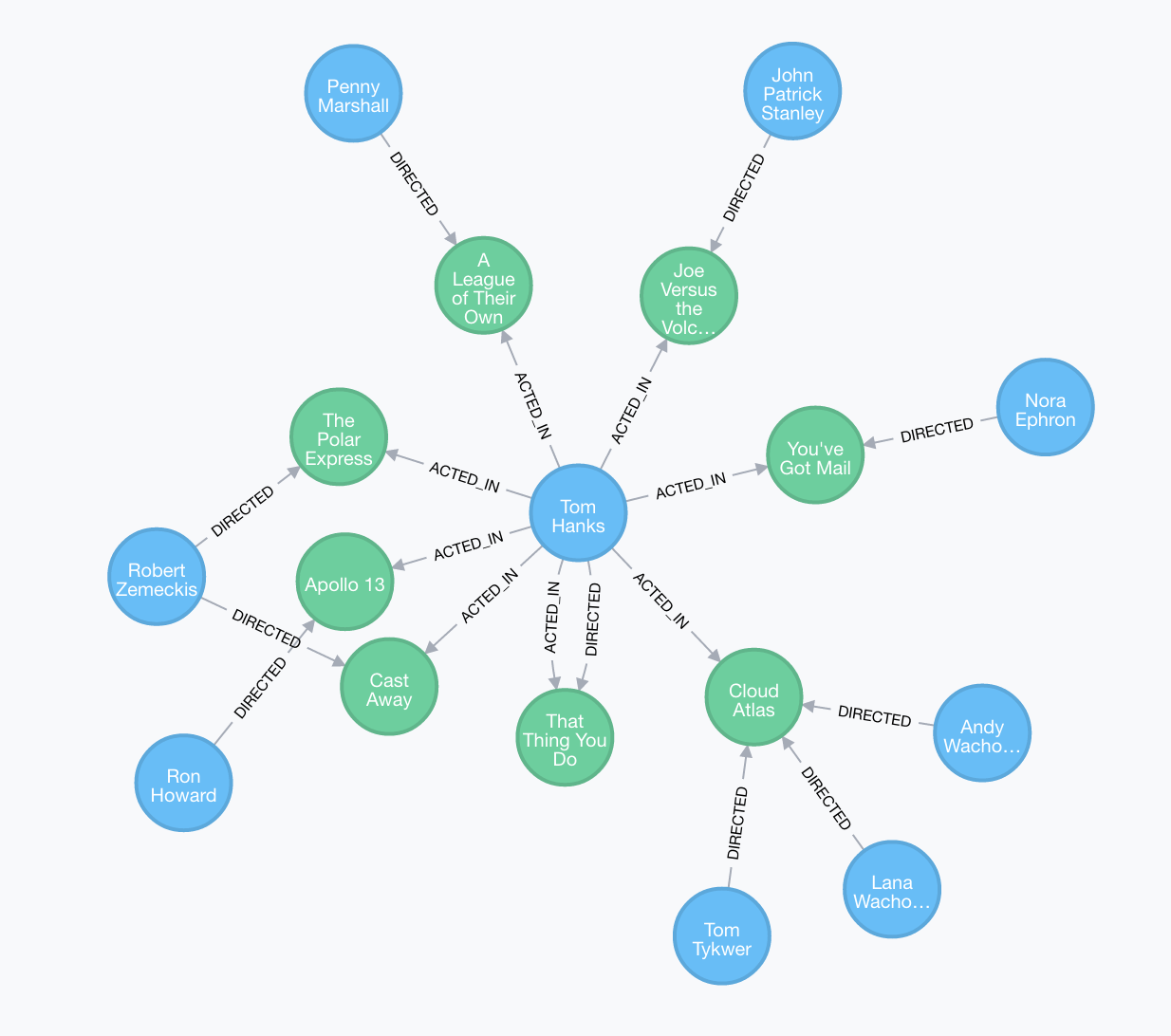
Credit: Neo4j tutorial
GraphHack
Why am I blogging this?
Yesterday I had my first exposure to the type of NoSQL databases I just described I have to say I had a blast. I was challenged from the very beginning since the mental framework that you must have to query and organize the data is very different from a traditional database.
I spent the evening at GraphHack which was the hackathon hosted by Neo4j before the GraphConnect Conference. Neo4j is the company that created the open-source databse neo4j, which is a graph based database. The point of the competition was to use the technology and be able to do some interesting investigative journalism, which was the reason they gave us the dataset for the Panama Papers, Hillary Clinton’s released email and pointed us in the direction to other government datasets.
My team researched campaign finance in the city of San Diego in an effort to uncover interesting facts and maybe win a prize. I spent most of the time figuring out how to help the team, cleaning some of the data and learning excel to clean the data in google drive.I knew very little (nothing) about Cypher, which is the query language developed by the company for their database so I thought up interesting queries while I kept asking questions. Overall it was a teaching experience since I got to learn about a new technology. In the end we discovered that the largest donations to the San Diego County elections were coming from out of state, which was pretty interesting in my opinion. Somehow that paid off since our team won third place!
Many thanks to B, N, since they carried the team, I was just happy to help. Also thanks to F for pushing us to think out of the box, it was very helpful.
Investigating what th government does with money turned out to be very fun, so I will probably explore this dataset a bit more. Thanks for reading!